Noam Chomsky Contribution to Computer Science (Put Very Simply)
Noam Chomsky was everything but a computer geek. However, his work contributed majorly to computer science and programming.
Posted onby Daniel Paiva
Introduction to Noam Chomsky and His Contributions
Noam Chomsky is, according to Wikipedia, a linguist, philosopher, cognitive scientist, historian, social critic, political activist, a father, a 91-year-young gentleman and NOT a programmer or computer scientist, however he made some major contributions to these fields. For starters, he had a huge influence in the theory of Formal Languages and is the creator of Hierarchy of Grammars aka Chomsky Hierarchy. This article is a brief explanation of what that hierarchy is.
(Just a note, I tried to wrote this text for everyone, regardless of mathematic or programming background, some of the language is not the same that would be used normally for academic articles. Do not use this as study material, but do use it as a resumed entry point to arouse your interest.)
The Four Types of Grammars in the Chomsky Hierarchy
Noam Chomsky categorized grammars in 4 different types and organized those in terms of complexity, from the most wide-ranging to the smallest group with the simplest grammars: Recursively Enumerable, Context-Sensitive, Context-Free and Regular grammars. We know this last one is the smallest because each type is contained in the one before it. All Regular grammars are Context-Free, Context-Free are Context-Sensitive and so on.
Regular Grammars and Finite State Automatons (FSA)
Understanding Regular Grammars
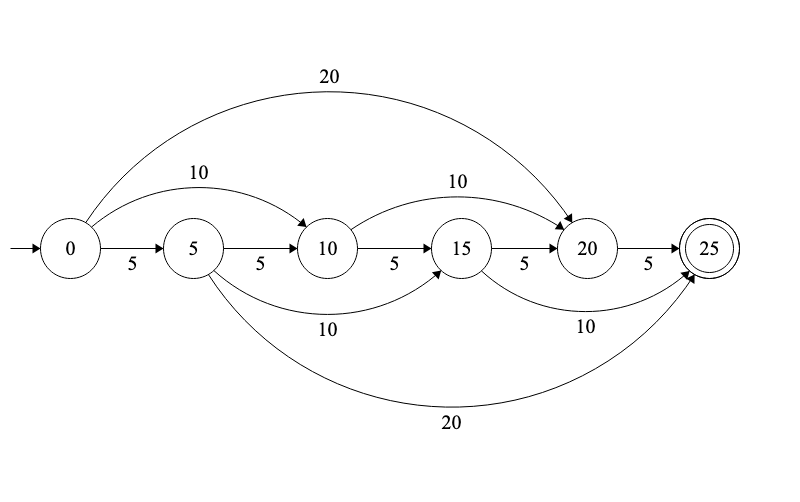
Regular grammars are the ones that are accepted by a Finite State Automaton (FSA). One example of a FSA is a parking meter (a very simple one that accepts 25 cents for one ticket). Being a Regular grammar means that this problem can be solved without the need for any kind of memory.
The FSA accepts 5, 10 and 20 cents coins. It moves accordingly, and when it reaches the ‘25’ state, it accepts. (I left out the cases where the machine is given more than 25 cents to avoid overcrowding this graph, assume that anything over 25 cents is accepted.)
How FSAs Work
FSAs are given an input and read it one element at a time, you give the parking meter one coin at a time and it decides for that particular coin what to do, but it does not know how many or which coins it received before.
Context-Free Grammars and Pushdown Automaton (PDA)
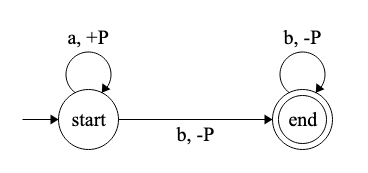
Context-Free are the grammars that are accepted by a Pushdown Automaton (PDA). These are a little more complex, they do need a memory, but they can be solved using just a stack. Imagine a system that allows you to purchase a ticket for a group of N people, and then you give it to a turnstile system that will rotate N times.
The ‘a’ is a person in the ticket, ‘b’ is a person trying to cross the turnstile. On the right of the comma, the ‘+P’ means we are pushing a ‘P’ to the stack, ‘-P’ means we are popping a ‘P’ from it.
You could not do that with an FSA, it would not know how many people passed already, because it does not have a memory, it is unable to count. A PDA works similarly to an FSA, but it does have a stack as a memory. In this example, the machine reads your ticket and pushes one mark (‘P’ in the example) to the stack for each person, then, every time the turnstile rotates once, it pops one element from the stack. At the end, it accepts it if the automaton is at a final state and the stack is empty.
Context-Sensitive Grammars and Linear Bounded Automaton (LBA)
How Context-Sensitive Grammars Are Defined
Context-sensitive grammars are the ones that are accepted by a Linear Bound Automaton (LBA), put very simply an LBA is a Turing Machine with a tape that is limited in size, meaning that we have to predict the maximum size of the output. Example:
{anbncn|n > 0} – all words that have only ‘a’, ‘b’, ‘c’, in that order, and have the same number of ‘a’, ‘b’ and ‘c’.
How an LBA Solves Problems
A PDA would not be able to decide on this problem, because it can only peek or pop the top of the stack, meaning that what it knows is very, very limited, it knows the last element it read now, but it will only know the second-to-last element, when it forgets the last, and for this case you need something a little better. An LBA solves this problem using the same memory used for the input, given a tape with N elements it will only need N spaces of the tape to decide if it is accepted or not.
Here is how it works: first of, we can verify if the word is of size 0, if so, we accept it, it is part of the language after all – specifically the word a0 b0 c0. If not, run this program.
(Keep in mind that for every step, if we find anything other than what we expect, we reject the word, for example, on the first step we expect an ‘a’ if we find a ‘b’ or a ‘c’, we reject the word).
1 – Read the first ‘a’ on the tape and replace it with ‘a*’, go to 2.
2 – move right on the tape until you find a ‘b’ and replace it with ‘b*’, go to 3.
3 – move right on the tape until you find a ‘c’ and replace it with ‘c*’, go to 4.
4 – move left on the tape until you find an ‘a*’ and then move right to read the element that comes after it:
4.1 – if it is an ‘a’ we replace it with an ‘a*’ and go back to 2.
4.2 – if it is a ‘b*’, it means we read all the ‘a’, go to 5.
(we reach this step after running steps 2 and 3 a second time, in those steps we have marked the second ‘b’ and ‘c’. And then, on step 4 the second time, we found the second ‘a*’ and move the needle right, we find the first ‘b*’.)
5 – move right on the tape and make sure that all elements are either ‘b*’ or ‘c*’. If we reach the end of the tape: Accept the word.
Recursively Enumerable Grammars and Turing Machines (TM)
The Power of Turing Machines
Recursively Enumerable grammars are the ones that are accepted by a Turing Machine (TM). A TM is a mathematical construct that represents a computer, meaning any grammar that is computable by a modern machine, can be computed by a TM.
How TMs Encompass Other Grammars
Put simply, this group encompasses every grammar that describes a problem that can be solved by a computer, including, of course, all the Regular, Context-Free and Context-Sensitive grammars. To define if a grammar lands on this group and not outside of the whole hierarchy is a very complex problem that goes beyond my qualifications and would take a whole other article to explain, but I hope this article piqued your curiosity enough to make you go and learn it on your own.
Conclusion and Further Reading
The Chomsky Hierarchy is essential to understanding computability, however it is just a small part of the whole picture, if you want to dive deeper into this theme, there is a lot more to find: “Introduction to the Theory of Computation” by Michael Sipser was recommended to me when I started, I would recommend it to you as well, if you are not much of a reader, Computerphile on YouTube has videos that dive a little deeper in to this subject. I should point out, I am not an expert in this field and this article is not a thorough explanation, but I do hope I managed to make you curious about this and hopefully you will be as fascinated by this subject as I am.
For businesses wanting to explore the application of formal languages in their operations, Exaud provides consulting services to guide you through the complexities of implementing language processing systems effectively.
We're not here to fill your inbox with generic tech news. Our newsletter delivers genuine insights from our team, along with the latest company updates.